Wat ChatGPT over jouw organisatie zegt begint bij llms.txt
Wat taalmodellen lezen, beïnvloedt wat klanten horen. Dat is precies waar llms.txt om draait.


Wanneer er niet meer op je site wordt gezocht, maar over je site
Steeds vaker stellen klanten hun vragen aan ChatGPT in plaats van in je zoekveld. De antwoorden komen dan niet rechtstreeks uit jouw website, maar uit wat het model denkt te weten. Dat kan kloppen, maar soms is informatie verouderd of onvolledig.
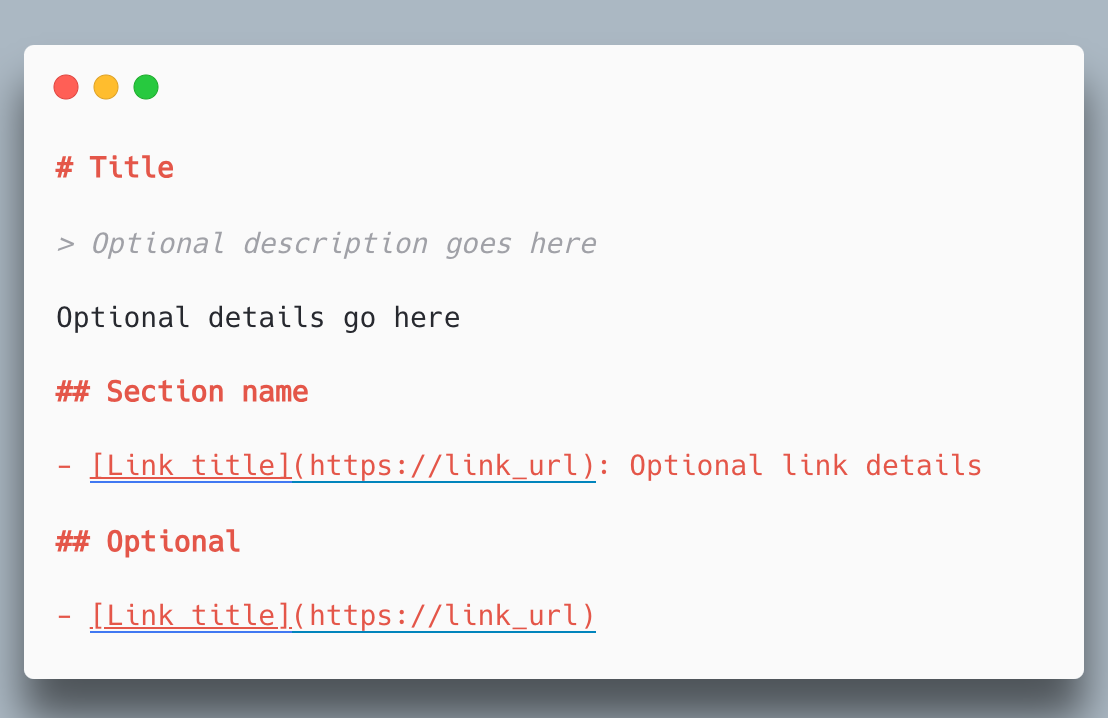
Een nieuw instrument: llms.txt
Om richting te geven aan wat taalmodellen over je bedrijf vertellen, ontstaat een nieuw hulpmiddel: llms.txt. Het werkt vergelijkbaar met robots.txt. Je kunt in een simpel tekstbestand aangeven wat je kernactiviteiten zijn, welke bronnen actueel zijn en welke termen liever niet worden gebruikt.
Het is geen volledige controle, wel een signaal dat modellen kunnen meenemen.
Praktische hobbels bij de invoering
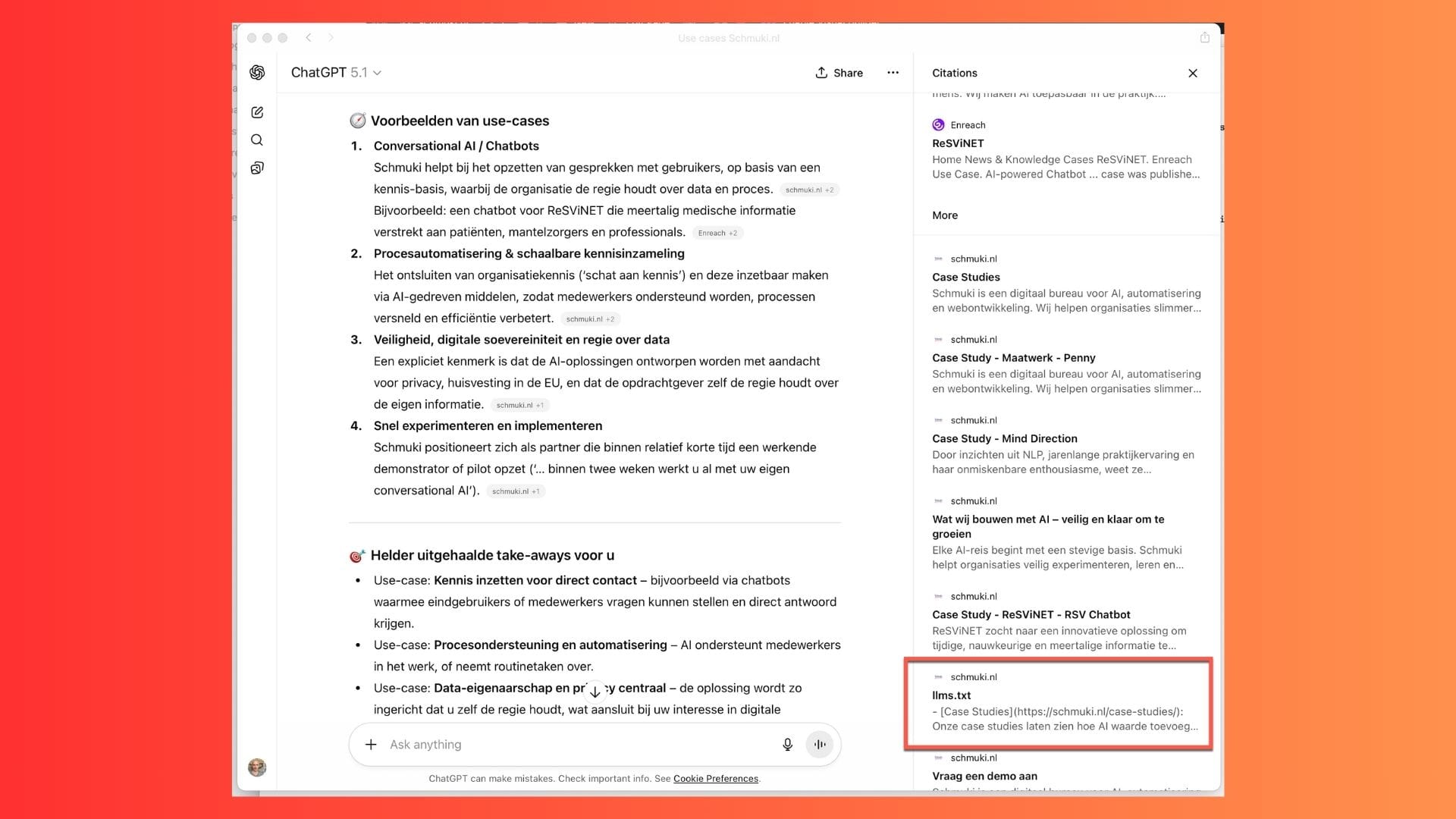
Ik heb llms.txt getest voor onze eigen site. Het schrijven van het bestand was eenvoudig. De hindernis zat in de toegankelijkheid. Onze hostingpartij blokkeerde standaard verzoeken van LLM-agents, wat leidde tot een 403-foutmelding. De file bestond, maar was niet zichtbaar voor het systeem dat hem moet lezen.
Na het verplaatsen van de DNS naar een CDN dat deze toegang wel toestaat, begon het te werken zoals bedoeld.
Wat nu belangrijk wordt: observeren
De komende tijd wil ik zien wat dit betekent. Wordt onze beschrijving consistenter? Wordt actuele informatie sneller opgepikt? De echte waarde zit in dat effect op langere termijn.
Ik schreef er al eens over op mijn Engelstalige blog:

Waarom dit telt voor bedrijven
Wanneer online vertrouwen cruciaal is, wil je niet dat anderen namens jou samenvatten wie je bent. Met llms.txt bied je een eigen, actuele referentie die misverstanden kleiner maakt en je digitale identiteit beter beschermt.